Asset-Based Data Orchestration: Lessons from Building a Multi-State Social Data Platform


Building reliable data platforms rarely fails because of scale alone. More often, reliability collapses under heterogeneity: multiple data providers, inconsistent schemas, partial updates, and unclear ownership.
While building a multi-state social data platform ingesting resource data from dozens of organizations, we discovered that reliability is not a property of pipelines. It is a property of data artifacts and their relationships.
1. Why Reliability Becomes a Systems Problem at Scale
The accompanying essay frames trust as something earned through consistent system behavior under real-world pressure. What that framing leaves implicit, but what became unavoidable in practice, is that reliability stops being a property of individual components very early on. Once multiple organizations, jurisdictions, and publishing surfaces are involved, reliability becomes an emergent property of the entire system.
For us, this meant that no single pipeline, connector, or database could be made "reliable enough" in isolation. Failures were rarely total. They were partial, localized, and often silent. The engineering challenge was not preventing all failure, but designing the system so that failures were isolated, detectable, and explainable.
That requirement drove nearly every architectural decision that followed.
2. System Overview
Technically, the platform ingests social service resource data from independent organizations operating across multiple U.S. states. Each organization exposes data via a different source system (for example iCarol, WellSky, VisionLink, RTM), with varying schemas, update cadences, and quality guarantees.
At a high level, the system consists of:
- Writers - per-tenant ingestion and transformation projects that:
- Fetch raw data from source systems via connector adapters
- Persist raw data into Snowflake source schemas
- Normalize and standardize data via DBT
- Apply enhancements such as geocoding or translations
- Readers - publisher processes that:
- React to completed writer runs, either bulk or incremental
- Publish curated artifacts to OpenSearch, MongoDB, and optionally Postgres
Snowflake acts as the system of record for intermediate and normalized datasets. Dagster coordinates the execution and materialization of data assets. DBT is used explicitly for set-based transformations, not orchestration.
Scale is not extreme in raw volume, but complexity is high: dozens of tenants, hundreds of tables per tenant, and frequent partial updates.
High-Level Architecture
The following diagram illustrates the writer → Snowflake → DBT → asset orchestration → readers pattern.
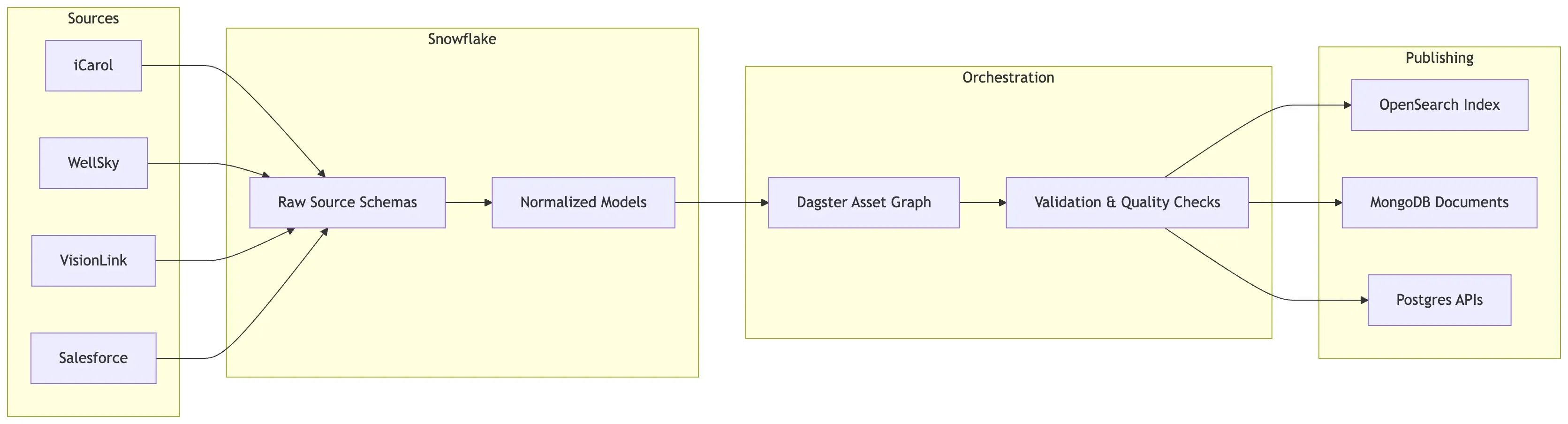
The platform is designed around asset lineage and normalization contracts, not pipelines.
3. Source Heterogeneity as the Dominant Constraint
The hardest constraint was not throughput or storage. It was heterogeneity.
Each data provider differed along several axes simultaneously:
- Schema shape: even when nominally "the same" entities existed, fields varied
- Semantics: identical fields often meant subtly different things
- Update cadence: some sources updated continuously, others weekly or ad hoc
- Quality guarantees: missing fields, stale records, or partial exports were common
Early on, we underestimated how strongly these differences would dominate system design. Attempting to treat ingestion as a uniform, pipeline-shaped process led to brittle assumptions and cross-tenant coupling.
The system only became manageable once heterogeneity was treated as fundamental, not incidental.
4. Normalization (HSDS, SDOH or Equivalent) as an Architectural Contract
Normalization into an HSDS-like model was not implemented as a downstream convenience. It became an architectural contract.
All downstream consumers, internal and external, implicitly rely on the guarantees of the normalized model: stable fields, predictable relationships, and documented semantics. That meant normalization could not be "best effort" or delayed until the end of a pipeline.
In practice:
- Raw source data is written verbatim into Snowflake source schemas
- DBT ELT projects transform this raw data into standardized intermediate models
- DBT STAGE projects apply tenant-specific adaptations while preserving the contract
This separation made it explicit where interpretation happens. If a field is wrong in the normalized model, the question becomes which contract was violated, not "what broke in the pipeline".
5. What We Got Wrong Initially
Several early assumptions did not survive contact with reality.
Pipeline-first thinking
We initially modeled work as long-running jobs. This obscured which intermediate datasets were durable, reusable, or safe to depend on. Debugging often meant rerunning more than necessary.
Manual validation
Data quality checks lived outside the orchestration layer. Engineers and analysts manually inspected outputs, which worked at small scale but failed under concurrency and time pressure.
Shared failure domains
Multiple tenants often shared execution paths. A failure in one tenant’s ingestion could block or delay others, even when their data was unrelated.
None of these issues were catastrophic individually. Together, they made reliability depend on human attention.
6. Transitioning to Asset-Based Data Orchestration with Dagster
The shift to asset-based orchestration was driven less by tooling preference and more by a change in mental model.
Instead of asking "what jobs should run?", we started asking:
- What data artifacts must exist?
- What do they depend on?
- How fresh do they need to be?
- What constitutes success or failure for this artifact?
Dagster assets provided a way to encode those questions directly.
A simplified example from a writer project shows how DBT models are treated as assets rather than opaque steps:
# writer-xyz/assets.py (excerpt) from dagster_dbt import load_assets_from_dbt_project dbt_elt_assets = load_assets_from_dbt_project( project_dir="dbt_elt", profiles_dir="dbt_elt", )
This does not explain how DBT runs. It declares that the resulting tables are first-class assets with lineage and state.
Once assets replaced jobs as the primary abstraction, freshness, lineage, and partial recomputation became explicit rather than implicit.
7. Partitioning for Failure Isolation
Partitioning was critical for isolating failures.
We partitioned primarily along tenant and state boundaries, not time. This reflected operational reality: data issues almost always affected a single organization or region.
In Dagster terms, this meant:
- Separate writer projects per tenant
- Independent schedules and sensors
- Asset materializations scoped to a tenant’s data domain
A failure in one writer no longer blocked publishing for others. More importantly, remediation could be targeted and auditable.
8. Data Quality Embedded in the Asset Graph
Data validation moved into the asset graph itself.
Instead of post-hoc checks, validations became explicit dependencies. If a validation asset failed, downstream assets simply did not materialize.
An example pattern used across writers:
@asset def validate_staging_tables(staging_tables): assert staging_tables.count_missing_ids() == 0
This is intentionally simple. The key point is not the check itself, but that failure is structural. The system records that an expected artifact does not exist, rather than silently publishing bad data.
This shifted failure detection earlier and reduced the blast radius of errors.
9. Operational Outcomes
Day-to-day operations changed in several concrete ways:
- On-call work shifted from rerunning pipelines to inspecting asset lineage
- Partial backfills became routine rather than exceptional
- Publishing delays were easier to attribute to specific upstream causes
- New tenants could be added without increasing shared operational risk
- None of this eliminated operational effort. It made that effort more focused and less reactive.
10. Open Trade-offs and Unresolved Questions
Some challenges remain unresolved:
- Cross-tenant schema evolution still requires coordination and discipline
- Observability across Snowflake, DBT, Dagster, and downstream stores is fragmented
- Cost attribution at the asset level is still coarse-grained
- Human review remains necessary for certain semantic validations
With more time, we would invest earlier in unified observability and more formal schema versioning.
11. Why These Lessons Matter Beyond This Platform
These lessons are not unique to this system.
Any platform operating in civic tech, govtech, or environmental data shares similar constraints: multiple data producers, uneven quality, and real-world consequences for failure.
The core takeaway is not "use asset-based orchestration", but treat data artifacts as obligations. Once that shift happens, many architectural decisions become clearer.
Reliability stops being something you hope for and becomes something you can reason about.
Final Thoughts
The biggest lesson from this platform was not about any particular tool. It was about how we model the system itself.
Once data artifacts became the core abstraction, many reliability problems became easier to reason about. Failures became visible, dependencies became explicit, and operational work shifted from firefighting pipelines to managing data contracts.
For data platforms operating across heterogeneous sources, this shift can be the difference between a system that merely runs - and one that can be trusted.
FAQ
What is asset-based data orchestration?
Asset-based data orchestration treats data artifacts (tables, datasets, models) as the primary units of orchestration instead of pipelines or jobs. Systems like Dagster allow teams to define dependencies between assets, enabling better lineage tracking, partial recomputation, and failure isolation.
Why is asset-based orchestration useful for complex data platforms?
In large systems with many data producers and consumers, failures are rarely binary. Asset-based orchestration makes dependencies explicit, allowing teams to:
- isolate failures
- recompute only affected datasets
- track lineage across transformations
- enforce data quality checks before publishing
How does Dagster differ from traditional pipeline orchestrators?
Traditional orchestrators schedule jobs or workflows. Dagster emphasizes data assets and lineage. This enables better visibility into:
- what datasets exist
- what produced them
- what depends on them
- whether they meet freshness or quality requirements
When should teams adopt asset-based orchestration?
Asset-based orchestration becomes particularly valuable when systems have:
- many data sources
- heterogeneous schemas
- multiple downstream consumers
- partial or incremental updates
- strict reliability requirements
These conditions are common in multi-tenant data platforms and civic tech systems.
Does asset-based orchestration replace tools like DBT?
No. Asset-based orchestration complements transformation tools like DBT. In many architectures:
- DBT performs set-based transformations
- Dagster manages asset lineage, dependencies, scheduling, and validation
This separation keeps orchestration and transformation responsibilities clear.