


Partial Catchment Delineation for Scalable Inundation Modeling and Machine Learning



A System-Oriented Approach to Scalable Hydrological Feature Engineering
Traditional watershed delineation wasn't designed for machine learning at scale. The standard approach treats each watershed as a complete, self-contained unit, which makes sense when you're studying individual rivers. But it creates real problems when you need to train models across hundreds of locations.
We ran into this on a recent flood prediction project. The study area had almost no hydrological data, no stream gauges, no riverbed surveys, nothing you'd typically use for hydraulic modeling. So we trained an LSTM model to predict discharge instead. It worked, but there was a catch: the model could only predict flow at watershed outlets. One outlet per watershed meant we didn't have enough training points.
The obvious solution was to create more outlets by subdividing watersheds along the river. But traditional catchment boundaries overlap heavily when you do this, which breaks parallel processing and makes selective updates nearly impossible. We needed many independent spatial units for the ML model, but we also needed to preserve the downstream flow aggregation that hydrological modeling depends on.
Our solution was to delineate watersheds at the reach level instead. Each reach gets its own partial catchment, smaller units that remain hydrologically valid but can be computed and updated independently. It's a compromise between what the data pipeline needs and what the hydrology requires.
Getting the geometry right was only part of the problem. We tested multiple DEM sources, modified the river network repeatedly, and needed to recompute catchments constantly during development. Treating delineation as a one-time preprocessing step wasn't viable. We needed to version every intermediate result, recompute selectively when inputs changed, and compare outputs across iterations.
This pushed us toward Dagster's asset model. Instead of treating catchments as temporary pipeline outputs, we manage them as persistent spatial assets with explicit dependencies and lineage tracking.
The following sections cover the hydrological rationale, the technical implementation, and how asset orchestration made this approach practical for production use.
Catchment Delineation in the Context of Inundation Modeling
Inundation modeling relies on an accurate representation of how water accumulates and propagates through a river network. Traditionally, this begins with watershed delineation derived from a digital elevation model, followed by hydraulic simulation over the resulting domain. When applied to large regions, however, this workflow introduces practical limitations. Entire catchments must be processed as single units, even when only a small portion of the river network is relevant for a given prediction or model update.
From a data engineering perspective, this creates an undesirable coupling between upstream and downstream regions. A change in DEM preprocessing, stream burning strategy, or river vector alignment forces recomputation of large spatial extents, even when the change is localized. This coupling becomes a bottleneck when experimenting with multiple configurations or when operating a system that must adapt continuously to new data.
The core insight behind partial catchment delineation is that hydraulic dependency flows downstream, but computational dependency does not need to. By separating catchments into smaller, reach-aligned units, it becomes possible to preserve hydrological correctness while dramatically improving computational flexibility.
The Core Idea: Reach-Level and Progressive Catchments
We segmented each river into short reaches (100 m) and delineated a catchment for each reach. From those building blocks we constructed larger, progressively downstream catchments.
The method introduced here distinguishes between two complementary spatial constructs: reach-level catchments and progressive catchments.
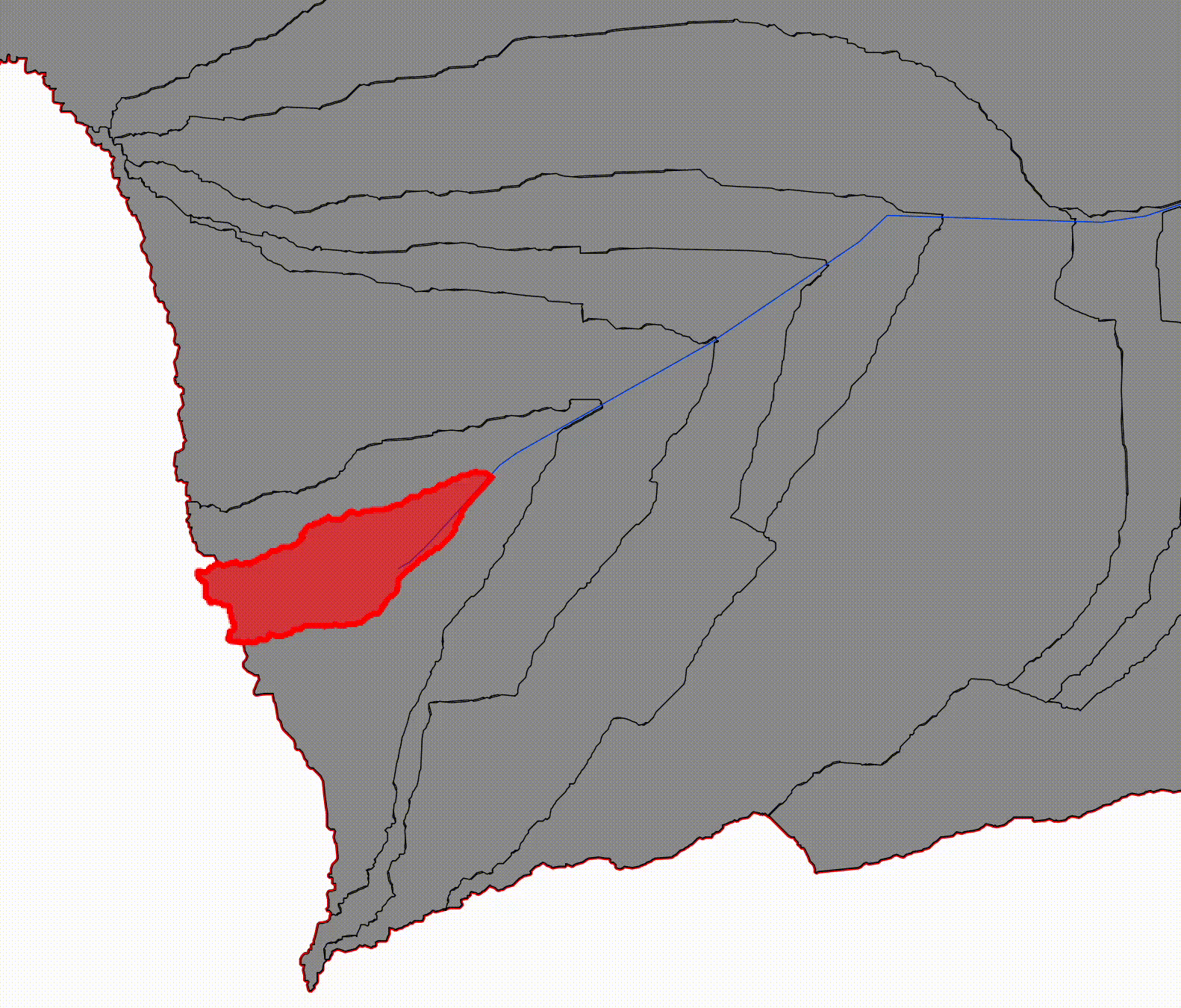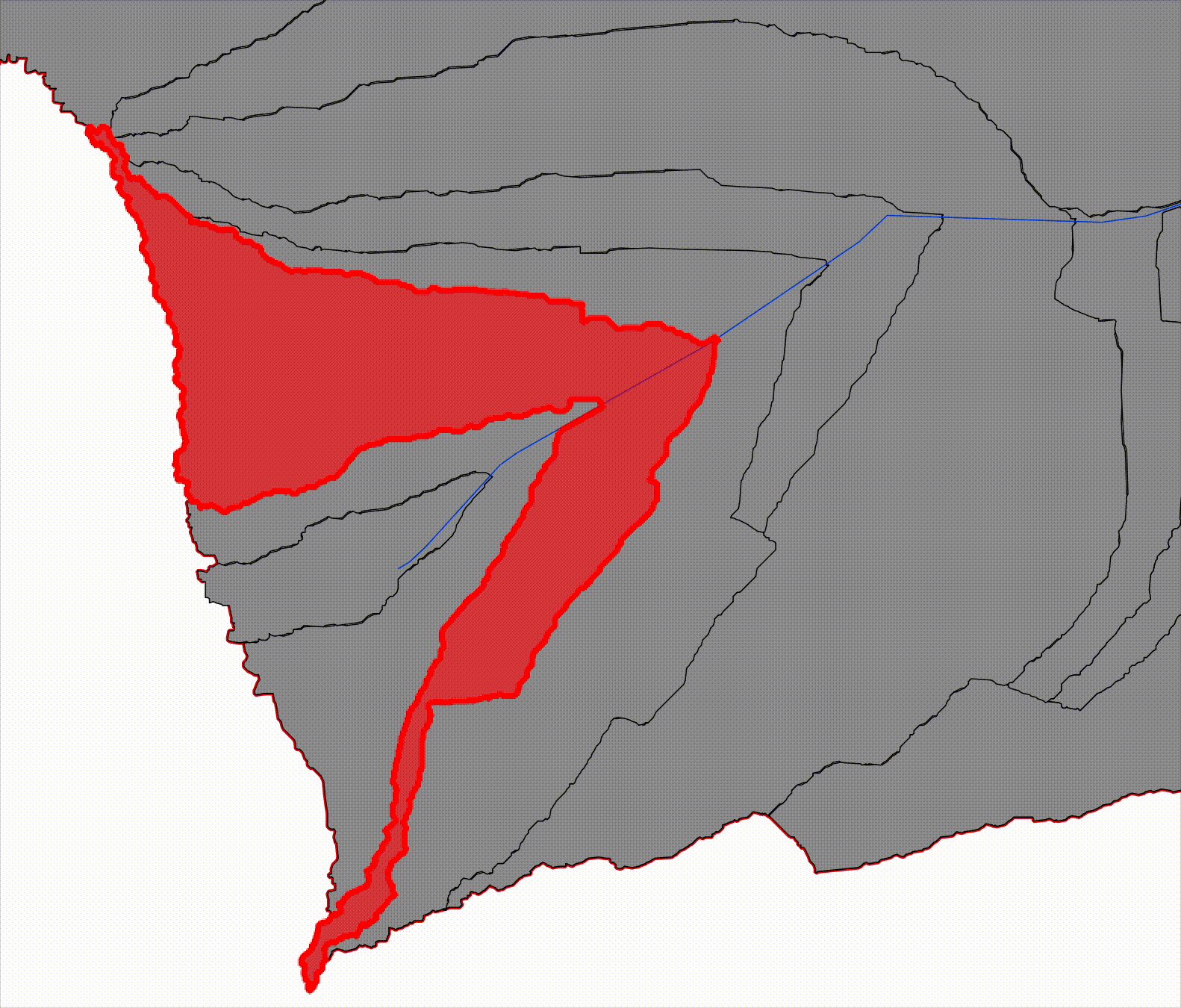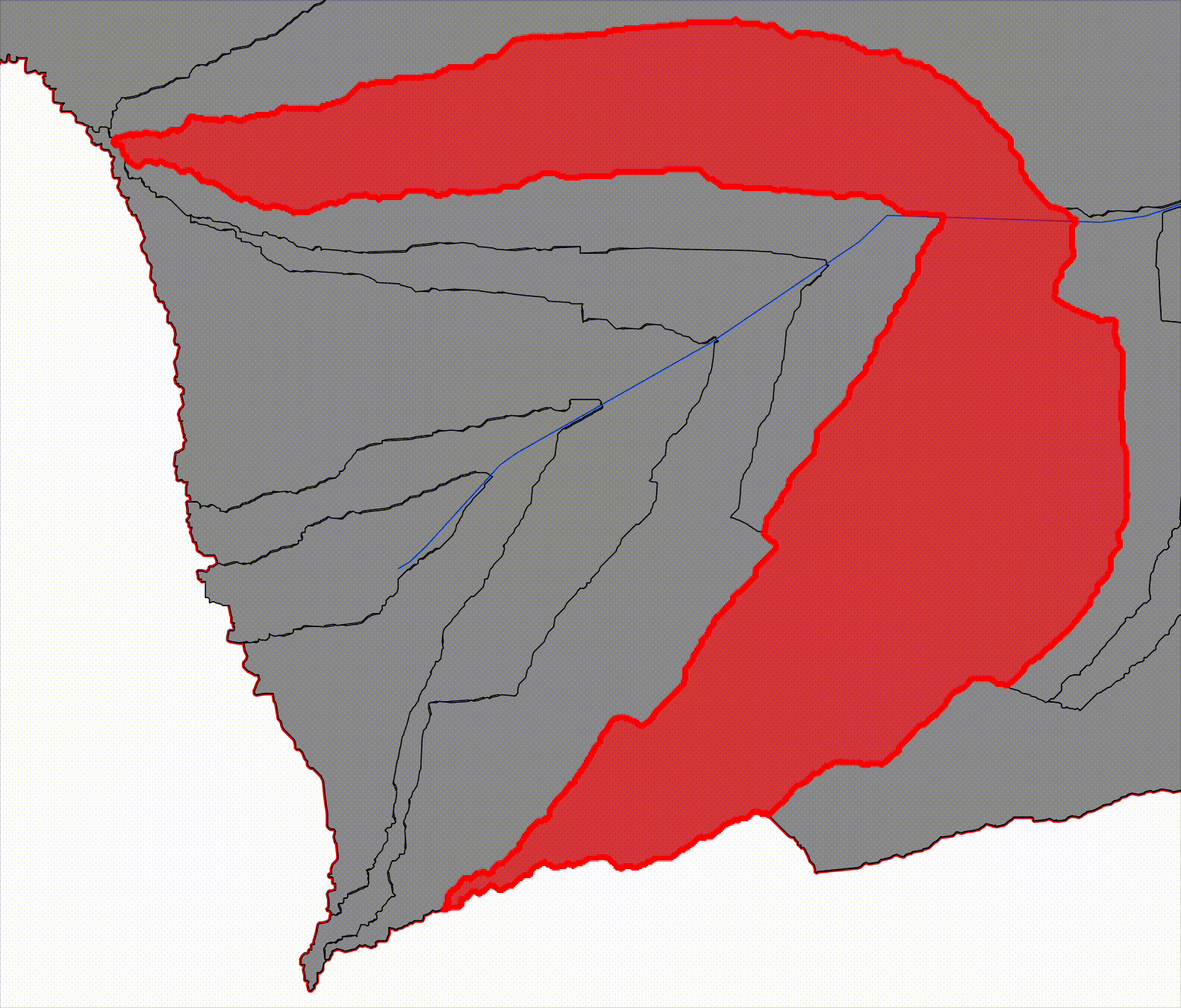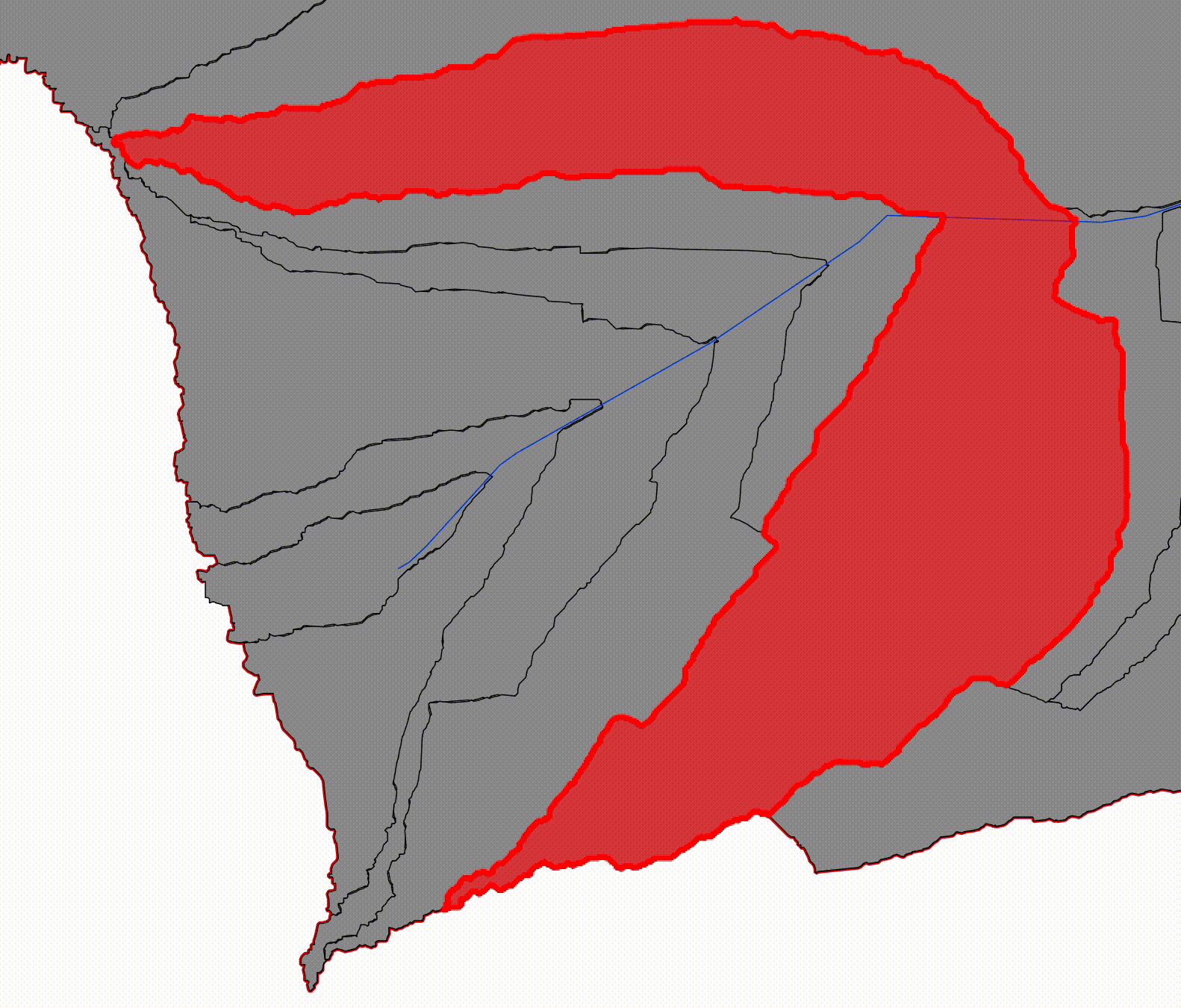
Reach Catchments (non-overlapping)
Reach-level catchments are defined for individual river segments, bounded upstream by the nearest confluence and downstream by the segment's outlet. These units do not overlap and collectively partition the drainage area of the river network. Their non-overlapping nature makes them well suited for parallel processing, independent feature extraction, and localized recomputation.
Visualize the landscape divided into narrow, adjacent drainage areas:
- Each reach catchment drains only to its own 100 m river segment
- None of them include upstream contributions
- Their boundaries tile the basin without overlaps
Progressive Catchments (overlapping by design)
Progressive catchments, by contrast, represent the cumulative upstream area contributing to a given river reach. Each progressive catchment is constructed by aggregating all upstream reach-level catchments along the river network. This structure mirrors traditional hydrological reasoning and provides a direct bridge to downstream hydraulic modeling.
Now start combining those catchments as you move downstream:
- Progressive Catchment 1 = Reach 1
- Progressive Catchment 2 = Reach 1 + Reach 2
- Progressive Catchment 3 = Reach 1 + Reach 2 + Reach 3
Visually:
- the first progressive catchment is small and upstream
- each subsequent one contains the previous
- downstream catchments fully envelop upstream ones
This is why we call them progressive: each one represents the basin area contributing flow up to that point along the river.
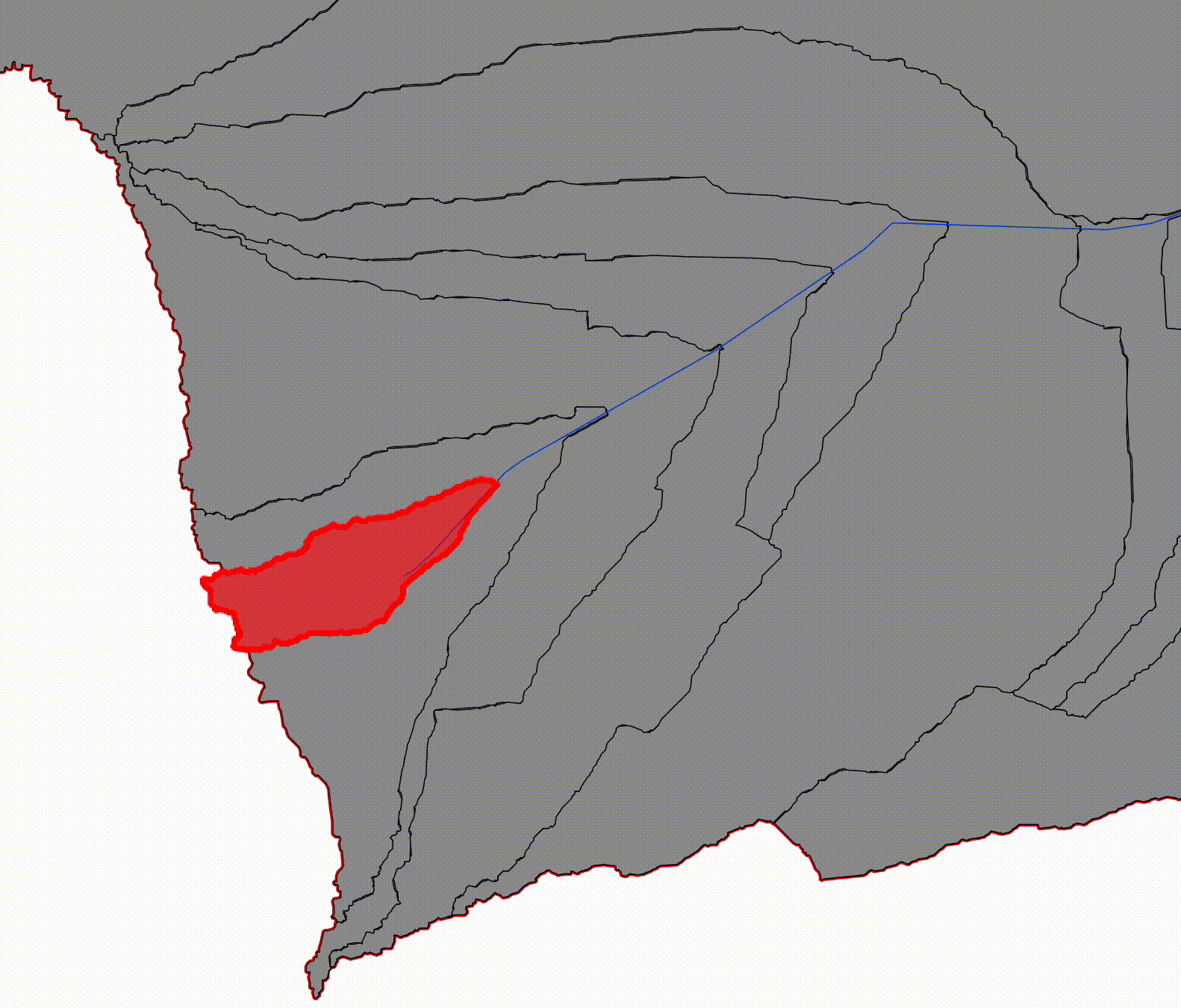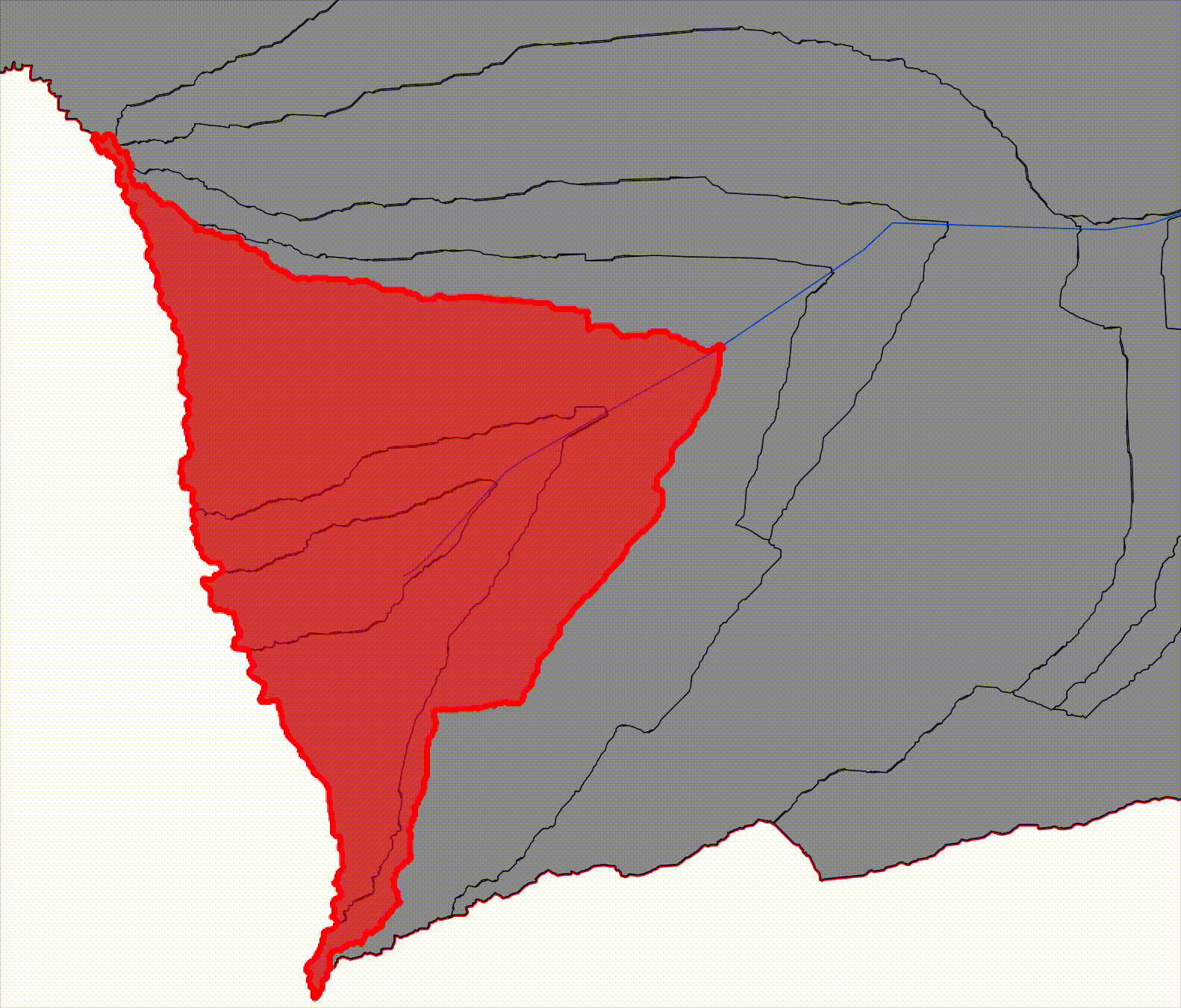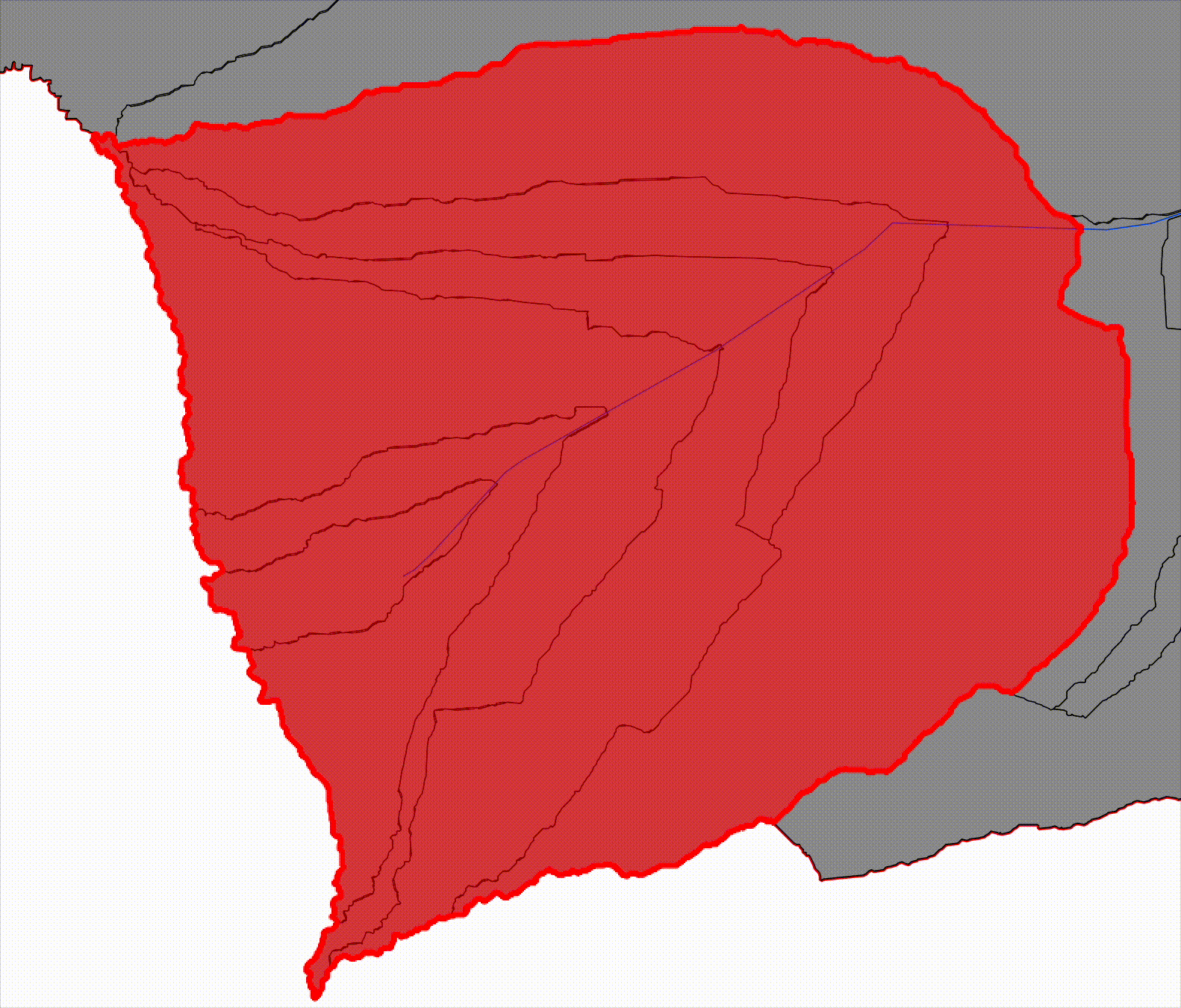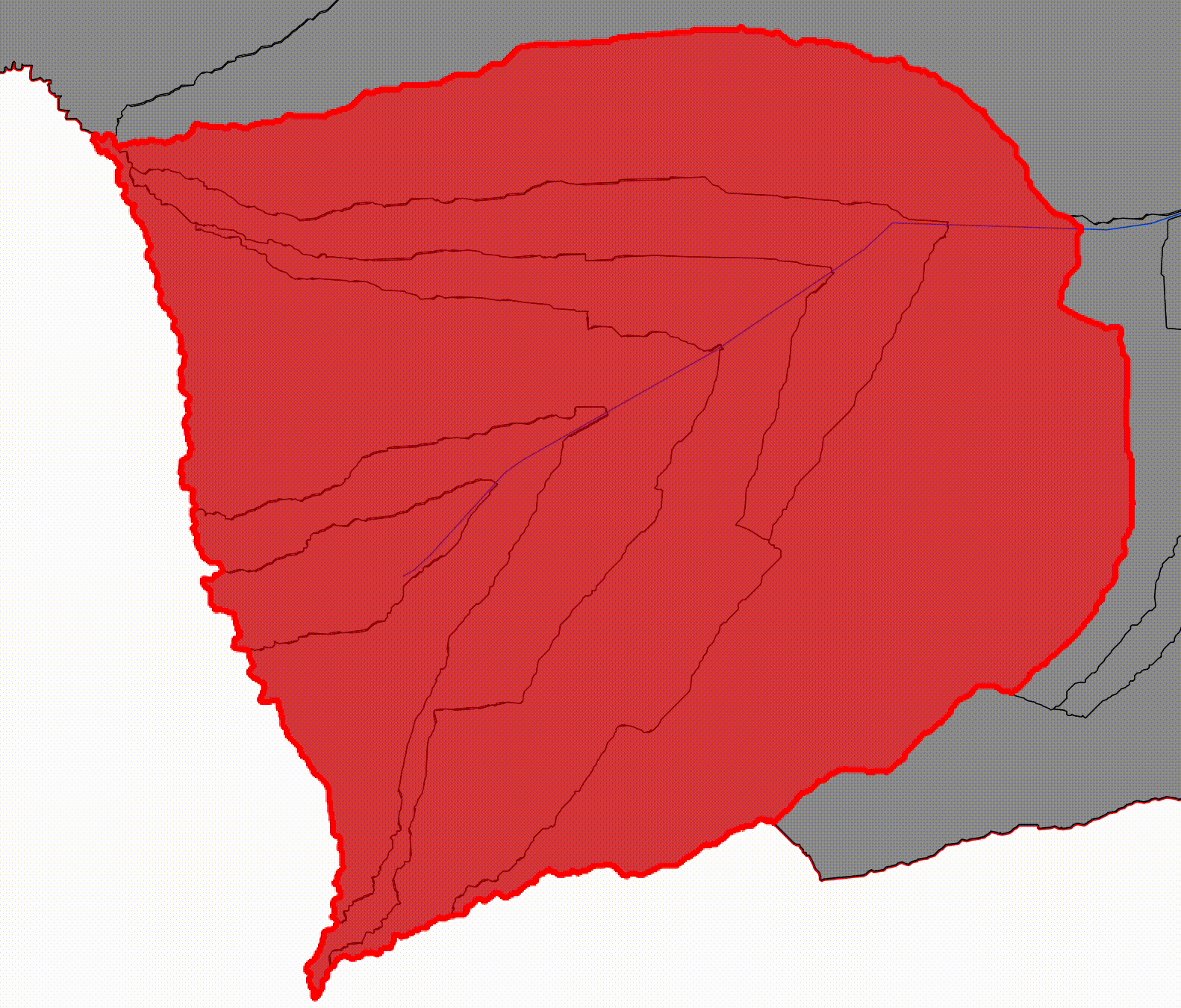
By maintaining both representations explicitly, the system can operate at two levels simultaneously. Reach-level catchments support scalable computation and machine learning workflows, while progressive catchments preserve the physical context required for inundation modeling.
Why not delineate progressive catchments directly?
We could have. It would actually be simpler than whatever we're actually doing. But:
- We also needed the reach catchments for inundation simulation later
- Running delineation logic twice felt like a smell
So we delineate once, and compose later.
Tributaries
Where a tributary joins:
- its reach catchments are merged into the progressive catchment only after the confluence
- upstream progressive catchments on the main stem remain unaffected
In other words:
- reach catchments are spatial building blocks
- progressive catchments are cumulative assemblies of those blocks
What the Two Catchment Types Are Used For
Progressive catchments → model training
Our LSTM predicts discharge at outlet points. For each progressive catchment, we derive features such as precipitation, temperature, humidity, pressure, the aridity index, and others.
All inputs are provided as raster datasets. Catchment geometries are used as spatial masks to extract and aggregate pixel values.
This workflow requires repeated spatial joins, raster masking, and temporal aggregation over large geospatial datasets. We implement and orchestrate these pipelines using Dagster, which allows us to manage dependencies, partition computations, and scale processing across large spatial-temporal datasets.
Reach catchments → inundation mapping
Each reach gets its own discharge estimate (derived from differences between progressive catchments), which later feeds the inundation simulation.
Once reach-level and progressive catchments are established, they become the foundation for feature extraction. Terrain attributes, land cover statistics, soil properties, and hydrological indices can be computed independently for each reach-level catchment. These features serve as inputs to machine learning models predicting discharge or inundation extent.
Progressive catchments then provide a natural mechanism for aggregating upstream contributions. Features derived at the reach level can be accumulated downstream in a controlled, traceable manner. This separation simplifies both training and inference: models operate on consistent, non-overlapping units, while hydraulic context is reintroduced through aggregation.
At this stage, the delineation method transitions from a GIS exercise into a data orchestration problem. Each derived feature depends on specific preprocessing choices, spatial units, and upstream dependencies. Managing these relationships manually quickly becomes infeasible.
DEM (Digital Elevation Model) Preprocessing
Implementing partial catchment delineation at high spatial resolution exposes a range of practical challenges. Reliable catchment delineation depends far more on DEM preprocessing than on the delineation algorithm itself.
High-resolution DEMs (1 m × 1 m in our case) amplify artifacts that are negligible at coarser scales, including spurious sinks, artificial barriers, and noise-induced flow paths. Stream burning and sink filling become necessary, but their parameters introduce additional degrees of freedom that affect downstream results.
Below we summarize the preprocessing steps that proved essential for stable and repeatable results.
Depression filling
Raw DEMs frequently contain spurious sinks caused by:
- measurement noise
- vegetation and built structures
- interpolation artifacts
Left untreated, these sinks interrupt downstream connectivity and lead to fragmented or incomplete catchments. We therefore applied depression filling prior to any flow calculations.
Our goal was not to aggressively flatten terrain, but to ensure continuous drainage paths with minimal elevation modification. Priority-flood-style algorithms worked well in practice and preserved overall terrain structure.
Stream burning
Even after sink removal, we observed inconsistencies between modeled flow paths and known river locations. To address this, we burned the vector river network into the DEM by lowering elevations along river centerlines.
Aligning raster-based flow accumulation with vector river networks proved particularly sensitive. Small positional discrepancies between datasets can lead to misaligned pour points, fragmented catchments, or unrealistic drainage patterns. These issues are not purely geometric; they directly influence the stability and reproducibility of downstream features.
This step serves two purposes:
- it enforces hydrologically plausible drainage paths
- it reduces sensitivity to small elevation errors in flat or low-gradient terrain
Stream burning significantly improved watershed stability, especially near confluences and in wide floodplains where DEM gradients are weak.
Flow accumulation and its limitations
We initially experimented with flow accumulation to:
- identify channelized flow paths
- snap pour points automatically to areas of high contributing area
However, the high spatial resolution of the DEM (1 m × 1 m) introduced significant noise into flow accumulation outputs. Minor elevation perturbations resulted in fragmented or unrealistic accumulation patterns, making automated snapping unreliable.
As a result, we limited the use of flow accumulation and instead relied more heavily on burned-in river vectors and explicit reach endpoints for pour point placement.
During later experiments we found that using D-infinity for calculating flow paths rather than D8 significantly improved flow accumulation calculation, but due to it being discovered too late, we weren't able to implement it before the end of first phase of the project.
Spatial alignment issues
During development we discovered small but still significant horizontal offsets between the DEM and the river vector dataset, on the order of a few meters. At some point we discovered that our river geometries were offset by a couple of meters relative to the DEM.
These discrepancies led to:
- pour points falling outside effective drainage paths
- unstable catchment boundaries
- inconsistent results across neighboring reaches
- weird catchment boundaries
- several hours of existential doubt
While stream burning mitigated some of these effects, resolving DEM-vector alignment remains an important area for future improvement. This is still on our list of things to fix properly. For now, burning rivers into DEM somewhat alleviated the issue.
Rather than attempting to eliminate these uncertainties entirely, we treated them as explicit dimensions of experimentation. Different preprocessing strategies were preserved as separate artifacts, allowing their effects to be compared systematically. This approach only becomes feasible when intermediate results are treated as first-class entities rather than overwritten pipeline outputs.
Overall, careful DEM preprocessing proved essential not only for hydrologic correctness, but also for producing geometries stable enough to support downstream machine-learning workflows.
Implementation Outline
Below is a cleaned-up, simplified sketch of the workflow. The real code is longer, louder, and contains more comments written at 2 a.m.
# 1. Load DEM and preprocess filled_dem = fill_depressions(dem) burned_dem = burn_streams(filled_dem, river_lines) flow_dir = d8_flow_direction(burned_dem) # 2. Split rivers into fixed-length reaches reaches = split_lines(river_lines, segment_length=100) # 3. Create pour points at reach outlets pour_points = reaches.geometry.apply(get_downstream_endpoint) # 4. Delineate reach catchments reach_catchments = delineate_watersheds( flow_dir=flow_dir, pour_points=pour_points ) # 5. Build progressive catchments progressive = [] current = None for reach in ordered_downstream(reach_catchments): current = reach if current is None else union(current, reach) progressive.append(current)
The devil, as always, lives in:
- tributary joins
- reach ordering
- and spatial indexing performance
Joining tributaries means:
- identifying parent-child relationships between reaches
- merging reach catchments in the correct downstream order
- avoiding double-counting areas
Asset-Based Orchestration of Spatial Dependencies
To make this workflow operational, we modeled reach-level catchments, progressive catchments, and derived features as explicit assets within Dagster. Each asset represents a durable spatial artifact with well-defined dependencies on upstream inputs. Changes in DEM preprocessing, river network alignment, or feature definitions propagate through the asset graph in a controlled way.
This asset-oriented approach allows recomputation to be both selective and explainable. When a preprocessing parameter changes, only the affected reach-level catchments and their downstream aggregates are recomputed. Historical artifacts remain available for comparison, enabling systematic evaluation of alternative configurations.
Dagster's lineage tracking plays a critical role here. Each feature can be traced back through the chain of spatial transformations that produced it, providing transparency during debugging and model validation. Rather than reasoning about pipeline execution order, the system reasons about data state and dependency.
Operational Implications
Treating partial catchment delineation as an orchestrated asset graph changes the operational profile of inundation modeling workflows. Iteration becomes cheaper because recomputation is localized. Failures become easier to diagnose because dependencies are explicit. Experimentation becomes safer because previous states are preserved rather than overwritten.
Perhaps most importantly, this approach aligns hydrological reasoning with modern data platform design. Physical dependencies are respected, but they no longer dictate computational coupling. The system can evolve incrementally, accommodating new data sources, preprocessing strategies, and modeling approaches without requiring full recomputation of the spatial domain.
Lessons Learned
- DEM preprocessing is very important
- 1 m DEMs are great until you compute derivatives
- River vectors and DEMs rarely agree — believe neither blindly
Conclusion
Segmenting rivers into reach-level catchments gave us:
- more training points
- spatially consistent features
- and a clean bridge between ML discharge prediction and inundation modeling
Partial catchment delineation proved valuable not because it produced a single optimal representation of a watershed, but because it enabled a shift in how spatial dependencies are managed at scale. By decomposing watersheds into reach-level units and reconstructing downstream context through progressive aggregation, we gained a representation that supports both hydrological correctness and computational scalability.
The effectiveness of this approach ultimately depended on its orchestration. Without an asset-oriented framework, the complexity introduced by multiple delineation strategies and iterative experimentation would quickly become unmanageable. By modeling spatial artifacts explicitly and preserving their lineage, we were able to integrate hydrology, machine learning, and geospatial preprocessing into a coherent, production-ready system.
If nothing else, this workflow taught us humility, patience, and how many ways water can refuse to flow downhill.
While this article focused on inundation modeling, the underlying pattern extends to any domain where high-resolution geospatial data meets iterative, data-driven workflows. Partial decomposition of space, combined with asset-based orchestration, offers a practical path toward scalable and trustworthy spatial modeling systems.













